Tidyverse: dplyr y tidyr
DplyR
El popular programador de R Hadley Wickham ha creado numerosos paquetes entre los que se encuentran tres de los cuales vamos a hablar en este curso: dplyr, tidyr y ggplot2. Aquí podéis encontrar el manifiesto del universo tidy o tidyverse donde los paquetes se construyen para que tengan sintonía los unos con los otros: https://cran.rstudio.com/web/packages/tidyverse/vignettes/manifesto.html

El paquete dplyr contiene una colección de funciones para realizar operaciones de manipulación de datos comunes como: filtrar por fila, seleccionar columnas específicas, reordenar filas, añadir nuevas filas y agregar datos.
Además, también contiene funciones que sirven para realizar una tarea que se denomina: split-apply-combine. Esto es, básicamente, calcular estadísticos (y otros) por grupos.
- Split: cortar por grupo
- Apply: aplicar la función
- Combine: combinar los grupos para dotarles de una estructura.
Esta tarea es muy común, ya la hemos visto y se puede realizar también con funciones que ya conocemos: aggregate y las de la familia apply.
La mayor ventaja de dplyr es que está orientado a dataframes. Además tiene otras ventajas que iremos descubriendo.
Cargamos el paquete dplyr en el espacio de trabajo:
# install.packages("dplyr") # para instalar el paquete
library("dplyr")Muchas de estas operaciones se pueden realizar de forma alternativa con funciones básicas de R, sin embargo, la sintaxis de dplyr:
Es más sencilla
Es más consistente
Está enfocada a datasets en lugar de a vectores
Además, combinándolo con la sinxtaxis pipes se extrae todo su pontecial.
Funciones importantes a recordar
Los siguientes son los verbos imprescindibles del paquete:
select(): seleccionar columnas
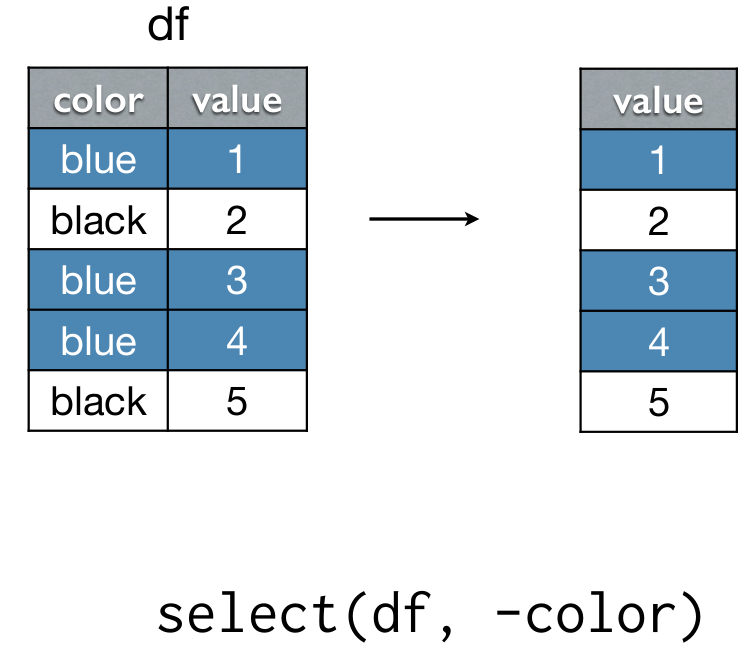
filter(): filtrar filas
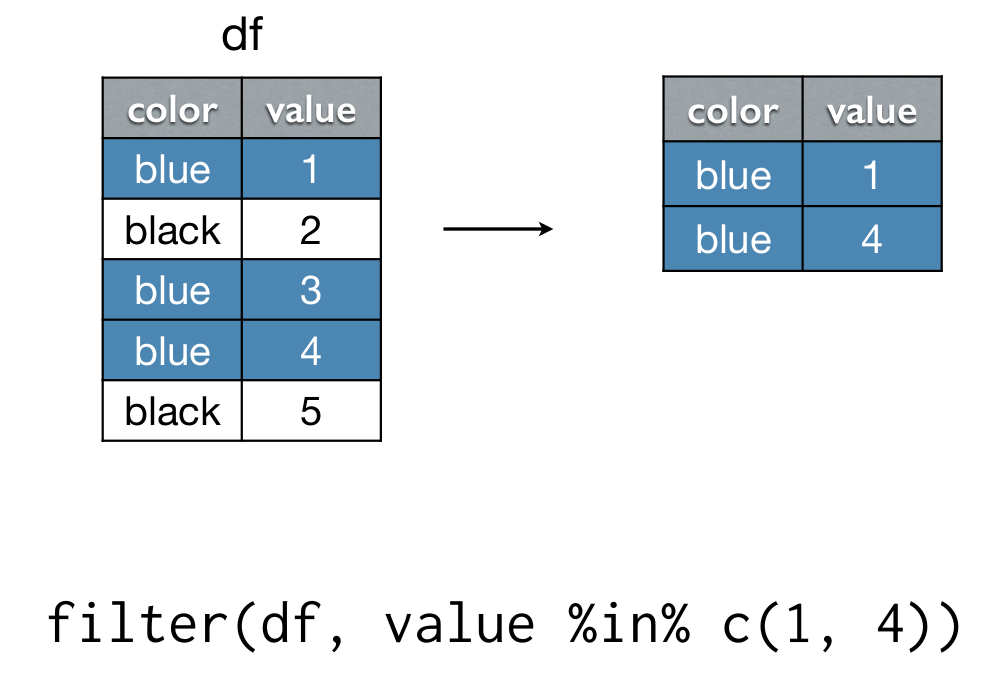
arrange(): reorderar filas
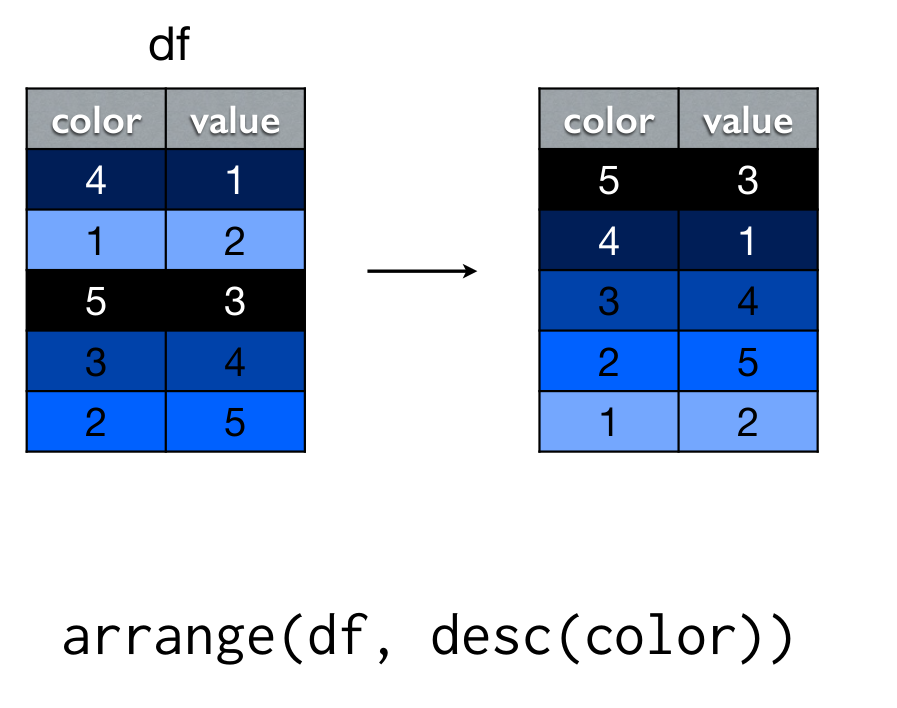
mutate(): crear nuevas columnas

summarise(): resumen de los valores

group_by(): permite operaciones por grupos del tipo split-apply-combine

Seleccionamos las 3 primeras columnas del dataset mtcars y mostramos la cabecera:
head( select( mtcars, mpg, cyl, disp ) )Utiliza la ayuda ?select_helpers para completar el siguiente código:
?select_helpers- Seleccionar las columnas que empiezan por d
select( mtcars, )select( mtcars, starts_with( "d" ) )- Seleccionar las columnas que terminan por p
select( mtcars, ...)select( mtcars, ends_with( "p" ) )Otras funcionalidades con select:
head(select( mtcars, -drat, -am ))head(select( mtcars, contains( "a" ) ))Veamos ahora la función filter:
head(filter( mtcars, mpg > 20, gear == 4))Seleccionar los sujetos con tipo de transmisión (am) 1 que, además, tienen 6 cilindros o menos.
filter( mtcars, am == ..., cyl ...)filter( mtcars, am == 1, cyl<=6)Seleccionar los sujetos que bien consumen menos de 21 mpg o bien tienen menos de 3 carburantes (carb) y menos de 4 engranajes (gear)
filter( mtcars, ...)"El operador para xxx o xxx es: | "filter( mtcars, mpg<21 | carb <=2, gear <4)A continuación, realiza los siguientes ejercicios con el resto de las funciones que conoces del paquete dplyr:
Ordena por cilindrada (cyl) y por desplazamiento (disp)
...(mtcars, ..., ...)arrange(mtcars, cyl, disp)Crea una nueva columna que indique los kilogramos que pesa el coche, sabiendo que 1 libra = 0.45 kg. La variable wt indica el peso en libras.
mutate(mtcars, ...)"No olvides multiplicar por 1000"mutate(mtcars, kg = 1000*wt*0.45)La función summarise() agrupa los valores en una tabla de acuerdo a la función que indiquemos. Calcula la media de disp usando la función summarise:
summarise(mtcars,...)summarise(mtcars, mean = mean(disp))Habitualmente se utiliza junto a group_by()
summarise(group_by(mtcars, cyl), max = max(disp))Piping datos
Pipes utiliza el resultado de una función como entrada de la siguiente. La función pipe, que pertenece al paquete magrittr se escribe así:
%>%.

Puede parecer rara al principio, pero necesitábamos una función definida por >, que implica que es una cadena (una sucesión de órdenes) y en R, para que un símbolo defina una función debe estar escrito entre porcentajes.
mtcars %>%
select( mpg:disp )%>%
headPara entenderlo bien, vamos a leer en voz alta la secuencia anterior:
Cogemos el dataset mtcars, seleccionamos la columnas de mpg a disp e imprimimos las primeras filas
Como vemos, sucesivamente se encadenan funciones dplyr, lo cual nos permite manipular los datos paso a paso, al igual que pensamos, evitando la creación de variables temporales por en medio para caputar la salida. Esto funciona porque la salida de las funciones dplyr es un dataframe y el primer argumento de las funciones dplyr es un dataframe.
Veamos esta secuencia:
head(select(select(mtcars, contains("a")), -drat, -am))¿Eres capaz de reescribirla utilizando pipes?
mtcars %>%
...mtcars %>%
select(-drat,-am )%>%
select(contains("a"))%>%
headHacerlo sin pipes no es un error. El problema es que hay que leerlo de dentro a fuera y es sencillo equivocarse (paréntesis que se pierden, argumentos que se separan de su función...). Además, esto es un ejemplo bastante sencillo pero para operaciones complejas, escribir código tal y como lo pensamos, esto es, de forma secuencial puede ser más sencillo.
Analiza la siguiente expresión y reescríbela usando pipes:
mtcars_filtered = filter(mtcars, wt > 1.5)
mtcars_grouped = group_by(mtcars_filtered, cyl)
summarise(mtcars_grouped, mn = mean(mpg), sd = sd(mpg))mtcars %>%
...mtcars %>%
filter(wt > 1.5)%>%
group_by(cyl) %>%
summarise(mn = mean(mpg), sd = sd(mpg))Analiza la siguiente expresión y reescríbela usando pipes:
my_cars <- mtcars[, c(1:5, 7)]
my_cars <- my_cars[my_cars$disp > mean(my_cars$disp), ]
my_cars <- colMeans(my_cars)
my_cars## mpg cyl disp hp drat qsec
## 15.520000 7.866667 346.760000 202.600000 3.219333 16.950000mtcars %>%
...my_cars <- mtcars %>%
select(c(1:5, 7)) %>%
filter(disp > mean(disp)) %>%
colMeans()
my_carsUtiliza la función cor() para calcular la correlación entre las variables de mtcars.
mtcars %>%
...mtcars %>% cor()Por último, introducimos la función n() que es específica de summarise(), mutate() y filter().
mtcars %>%
filter(wt > 1.5)%>%
group_by(cyl) %>%
summarise(mean = mean(disp), n = n())Autoevaluación
Practica lo que has aprendido descargando el siguiente fichero Rmd, abriéndolo con Rstudio y resolviendo las preguntas de autoevaluación.
Para descargar el Rmd de autoevaluación haz click derecho en el enlace anterior/ Guardar enlace como... y selecciona dónde quieres guardarlo.
Si al abrirlo con Rstudio observas caracteres extraños, selecciona File / Reopen with encoding / UTF-8 y ya se debe ver bien.
TidyR
El paquete tidyr contiene herramientas para crear tablas de datos tidy, donde cada columna es una variable, cada fila una observación y cada celda contiene un único valor. Tidyr ayuda a cambiar la forma de los datos (long o wide) entre otras exquisiteces.
Cargamos el paquete tidyr en el espacio de trabajo:
library("tidyr")
El paquete tidyr se centra en dos funciones:
gather()spread()
Y posee otras dos también muy importantes:
separate()unite()
Pares key-value
Para comenzar, vamos a exponer con un ejemplo la idea de pares key-value ya que es una terminología utilizada recurrentemente en las ayudas relacionadas con este paquete.
El siguiente conjunto de datos muestra el consumo de electricidad diario en 3 estancias de una casa:
set.seed(1)
consumo <- data.frame(
fecha = as.Date('2009-01-01') + 0:9,
habitacion = rnorm(10, 20, 1),
despacho= rnorm(10, 20, 2),
cocina = rnorm(10, 20, 4)
)
consumo La primera fila muestra 3 datos de consumo, una por estancia. Los números son los valores. ¿Qué valor van con qué estancia? Para saberlo miramos a los nombres de las columnas. Estos nombres son la clave o key. El valor o value 19.37355 está relacionado con la clave habitacion, por lo tanto es un par key-value. Para esa primera fila, hay tres pares key-value que están relacionados de forma única con la fecha 2009-01-01. En este caso, la fecha será el indetificador.
Formatos de tabla wide (ancha) y long (larga)
Wide y Long son términos que se utilizan para describir dos formas de presentar los datos en una tabla o en un dataframe.
- Wide: Cada variable de los datos se presenta en una sola columna
| persona | edad | peso |
|---|---|---|
| Alba | 25 | 65 |
| Perico | 26 | 70 |
| Maripili | 27 | 83 |
- Long: Una columna contiene todos los valores y otra columna contiene los nombres de todas las variables.
| persona | variable | valor |
|---|---|---|
| Alba | edad | 25 |
| Alba | peso | 65 |
| Perico | edad | 26 |
| Perico | peso | 70 |
| Maripili | edad | 27 |
| Maripili | peso | 83 |
Gather
La función gather coge muchas columnas y las hace colapsar en los pares key-value, repitiendo los nombres de las columnas tanto como se necesite.
Ahora habrá una variable que estará formada por los nombres de las columnas y todos los valores se encontrarán en una única fila.
No se necesita especificar los atributos uno a uno, sino que gracias a los pares key-value se puede escribir directamente el nombre que se quiere dar a las columnas para pasar de formato long a wide:
mtcarsG <- mtcars %>% gather(atributo, valor)
mtcarsGSin embargo, en otras ocasiones no será tan directo. Hazlo para el conjunto de datos consumo. ¿Qué está pasando aquí?
consumosPorEstancia <- ...
consumosPorEstanciaconsumosPorEstancia <- consumo %>% gather(atributo, valor)
consumosPorEstanciaLa columna fecha no queremos que se una a los atributos, sino que se mantenga como columna individual. Intentemos solucionar el problema:
Opción 1: hazlo igual pero quita "fecha"
consumosPorEstancia <- ...
...consumosPorEstancia <- consumo %>% gather(atributo, valor, -fecha)
consumosPorEstanciaOpción 2: Especifica en los argumentos de la función gather quién es data, quién es key y quién es value.
?gather
consumosPorEstancia <- gather(...)
consumosPorEstanciaconsumosPorEstancia <- gather(data = consumo, key = estancia, value = cons, habitacion, despacho, cocina)
consumosPorEstanciaSpread
Con la función spread podemos volver a estado anterior:
head(consumosPorEstancia)spread(consumosPorEstancia, estancia, cons)Prueba a pasar mtcarsG a formato long de nuevo.
head(mtcarsG)
mtcarsSpread <- mtcarsG %>% spread(key = atributo, value=valor)¿Se te ocurre alguna forma de que sí funcione? Impleméntala. Ayuda: rehaz el conjunto mtcarsG a partir de mtcars añadiendo lo que necesites ahora para poder aplicar spread.
# vamos a crear una columna identificadora que se denomina `car` y que tiene los nombres de las filas
mtcars2 <- mtcars
mtcars2$car <- rownames(mtcars2)
# a este conjunto le aplicamos el gather pero quitando el identificador
mtcarsG <- mtcars2 %>% gather(atributo, valor,-car)
# y ahora sí podemos revertirlo (gracias a que hay una columna de identificadores denomiada car)
mtcarsSpread <- mtcarsG %>% spread(key = atributo, value=valor)
head(mtcarsSpread)Unite
Sirve para pegar múltiples columnas en una sola:
head(mtcars)mtcarsU <- unite(mtcars, "vs_am", c("vs","am"))
head(mtcarsU)Junta las dos columnas vs y am utilizando los dos puntos como separador y, además, evita que se borren las columnas originales
mtcarsU2 <- unite(mtcars, ...)mtcarsU2 <- unite(mtcars, "vs:am", c("vs","am"), sep=":", remove=F)
head(mtcarsU2)Separate
Convierte una única columa en múltiples separando los caracteres que componen a la inicial.
Para ilustrar la función separate() vamos a utilizar un dataset sencillo:
df <- read.table("http://gauss.inf.um.es/datos/longlat.txt", sep=";", head=T)
dfLa intención es separar la columna Location en dos: lat y long. Para ello, primero eliminamos los paréntesis como sigue:
df2 <-df
df2$Location <- gsub("[()]", "", df2$Location)
df2Fíjate que hemos creado df2, un dataset intermedio (no es necesario, solo por claridad).
Y después utilizamos la función separate(), que tiene los siguientes argumentos
col: la columna a partirinto: los nombres que van a tener las nuevas columnassep: el carácter o expresión que separa
Inténtalo tú:
separate(df2, col = ..., into = ..., sep = ...)separate(df2, col = Location, into = c("lat","long"), sep = ",")Continuar con tabulaR
Una vez terminado este documento puede:
- Seguir con el siguiente módulo de tabulaR: Gráficos con ggplo2
- Volver al Modulo 1: Manipulación de datos
- Volver al portal de tabulaR
Última actualización: 20201116-1209 ![]()